Кеш
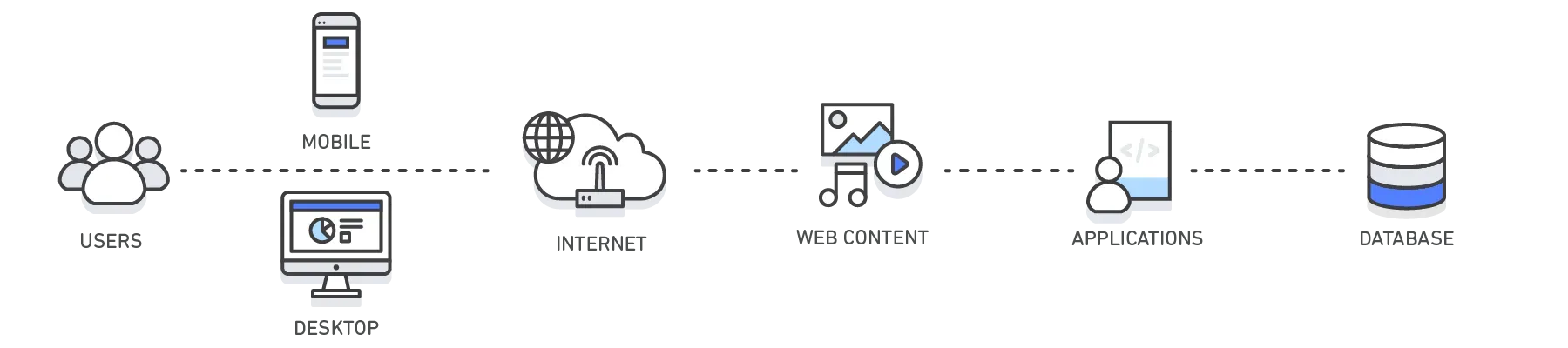
Что такое кэш?
В вычислительной технике кэш - высокоскоростной уровень хранения данных, который хранит подмножество данных, обычно временных по своей природе, так что будущие запросы на эти данные выполняются быстрее, чем это возможно при доступе к основному месту хранения данных. Кэширование позволяет эффективно повторно использовать ранее извлеченные или вычисленные данные.
Как работает кэширование?
Данные в кэше обычно хранятся в аппаратных средствах быстрого доступа, таких как оперативная память (Random-access memory), а также могут использоваться в сочетании с программным компонентом. Основная цель кэша - повысить производительность поиска данных за счет снижения необходимости доступа к более медленному уровню хранения.
В отличие от баз данных, данные которых обычно являются полными и долговечными, кэш обычно хранит подмножество данных на временной основе.
Обзор кэширования
Движки RAM и In-Memory
Благодаря высокой частоте запросов или IOPS (операций ввода-вывода в секунду), поддерживаемых системами RAM и In-Memory, кэширование позволяет повысить производительность поиска данных и снизить затраты при масштабировании. Для поддержки такого же масштаба при использовании традиционных баз данных и дискового оборудования потребовались бы дополнительные ресурсы. Эти дополнительные ресурсы увеличивают стоимость и все равно не позволяют достичь производительности с низкой задержкой, обеспечиваемой кэшем In-Memory.
Приложения
Кэши могут применяться и использоваться на различных технологических уровнях, включая операционные системы, сетевые уровни, включая сети доставки контента (CDN) и DNS, веб-приложения и базы данных. Вы можете использовать кэширование для значительного снижения задержки и повышения IOPS для многих приложений с высокой нагрузкой на чтение, таких как порталы вопросов и ответов, игры, обмен медиа и социальные сети. Кэшированная информация может включать результаты запросов к базе данных, вычислений, требующих больших вычислительных затрат, запросов/ответов API и веб-артефактов, таких как HTML, JavaScript и файлы изображений. Вычислительно-интенсивные рабочие нагрузки, манипулирующие наборами данных, такие как рекомендательные системы и высокопроизводительные вычислительные симуляции, также выигрывают от использования слоя данных In-Memory в качестве кэша. В этих приложениях доступ к очень большим наборам данных должен осуществляться в режиме реального времени на кластерах машин, которые могут состоять из сотен узлов. Из-за скорости основного оборудования манипулирование этими данными в дисковом хранилище является значительным узким местом для этих приложений.
Шаблоны проектирования
В распределенной вычислительной среде выделенный слой кэширования позволяет системам и приложениям работать независимо от кэша со своим собственным жизненным циклом без риска повлиять на кэш. Кэш служит в качестве центрального уровня, к которому можно обращаться из различных систем с собственным жизненным циклом и архитектурной топологией. Это особенно важно в системе, где узлы приложения могут динамически масштабироваться и расширяться. Если кэш находится на том же узле, что и приложение или использующие его системы, масштабирование может повлиять на целостность кэша. Кроме того, при использовании локальных кэшей они приносят пользу только локальному приложению, потребляющему данные. В среде распределенного кэширования данные могут охватывать несколько серверов кэша и храниться в центральном месте для всех потребителей этих данных.
Лучшие практики кэширования
При внедрении уровня кэширования важно понимать достоверность кэшируемых данных. Успешное кэширование приводит к высокому коэффициенту попаданий, что означает, что данные присутствовали при получении. Промах кэша происходит, когда найденные данные отсутствуют в кэше. Для соответствующего истечения срока хранения данных могут применяться такие элементы управления, как TTL (время жизни). Еще одним аспектом может быть необходимость высокой доступности кэш-среды, что может быть обеспечено механизмами In-Memory, такими как Redis. В некоторых случаях слой In-Memory может использоваться в качестве автономного уровня хранения данных в отличие от кэширования данных из основного местоположения. В этом сценарии важно определить соответствующие RTO (Recovery Time Objective - время, необходимое для восстановления после сбоя) и RPO (Recovery Point Objective - последняя точка или транзакция, зафиксированная при восстановлении) для данных, хранящихся в механизме In-Memory, чтобы определить, подходит ли это. Стратегии проектирования и характеристики различных движков In-Memory могут быть применены для удовлетворения большинства требований RTO и RPO.
Пример
В примере кода caches является свойством ServiceWorkerGlobalScope. Оно содержит объект CacheStorage, с помощью которого можно получить доступ к интерфейсу CacheStorage.
Примечание: В Chrome перейдите по адресу chrome://inspect/#service-workers и щелкните на ссылке
inspectпод зарегистрированным service worker, чтобы просмотреть протоколирование различных действий, выполняемых скриптом service-worker.js.
const CACHE_VERSION = 1;
const CURRENT_CACHES = {
font: `font-cache-v${CACHE_VERSION}`,
};
self.addEventListener("activate", (event) => {
// Delete all caches that aren't named in CURRENT_CACHES.
// While there is only one cache in this example, the same logic
// will handle the case where there are multiple versioned caches.
const expectedCacheNamesSet = new Set(Object.values(CURRENT_CACHES));
event.waitUntil(
caches.keys().then((cacheNames) =>
Promise.all(
cacheNames.map((cacheName) => {
if (!expectedCacheNamesSet.has(cacheName)) {
// If this cache name isn't present in the set of
// "expected" cache names, then delete it.
console.log("Deleting out of date cache:", cacheName);
return caches.delete(cacheName);
}
}),
),
),
);
});
self.addEventListener("fetch", (event) => {
console.log("Handling fetch event for", event.request.url);
event.respondWith(
caches.open(CURRENT_CACHES.font).then((cache) => {
return cache
.match(event.request)
.then((response) => {
if (response) {
// If there is an entry in the cache for event.request,
// then response will be defined and we can just return it.
// Note that in this example, only font resources are cached.
console.log(" Found response in cache:", response);
return response;
}
// Otherwise, if there is no entry in the cache for event.request,
// response will be undefined, and we need to fetch() the resource.
console.log(
" No response for %s found in cache. About to fetch " +
"from network…",
event.request.url,
);
// We call .clone() on the request since we might use it
// in a call to cache.put() later on.
// Both fetch() and cache.put() "consume" the request,
// so we need to make a copy.
// (see https://developer.mozilla.org/en-US/docs/Web/API/Request/clone)
return fetch(event.request.clone()).then((response) => {
console.log(
" Response for %s from network is: %O",
event.request.url,
response,
);
if (
response.status < 400 &&
response.headers.has("content-type") &&
response.headers.get("content-type").match(/^font\//i)
) {
// This avoids caching responses that we know are errors
// (i.e. HTTP status code of 4xx or 5xx).
// We also only want to cache responses that correspond
// to fonts, i.e. have a Content-Type response header that
// starts with "font/".
// Note that for opaque filtered responses
// https://fetch.spec.whatwg.org/#concept-filtered-response-opaque
// we can't access to the response headers, so this check will
// always fail and the font won't be cached.
// All of the Google Web Fonts are served from a domain that
// supports CORS, so that isn't an issue here.
// It is something to keep in mind if you're attempting
// to cache other resources from a cross-origin
// domain that doesn't support CORS, though!
console.log(" Caching the response to", event.request.url);
// We call .clone() on the response to save a copy of it
// to the cache. By doing so, we get to keep the original
// response object which we will return back to the controlled
// page.
// https://developer.mozilla.org/en-US/docs/Web/API/Request/clone
cache.put(event.request, response.clone());
} else {
console.log(" Not caching the response to", event.request.url);
}
// Return the original response object, which will be used to
// fulfill the resource request.
return response;
});
})
.catch((error) => {
// This catch() will handle exceptions that arise from the match()
// or fetch() operations.
// Note that a HTTP error response (e.g. 404) will NOT trigger
// an exception.
// It will return a normal response object that has the appropriate
// error code set.
console.error(" Error in fetch handler:", error);
throw error;
});
}),
);
});